
Author: Patrick Murphy
Analytics – a buzzword you rarely, if ever, associate with brewing. This mysterious subject seldom finds its way into the garages and kitchens of the modern-day homebrewer, and yet analytics has been the catalyst to thrust the beer industry into its next great paradigm shift. Professional breweries of all sizes recognize the dynamic ability of analytics to not only increase their bottom line, but also improve the progress, quality, and consistency of their beer in the most efficient way possible. As homebrewers, we tend to focus on more tangible means of improving our beer, often trusting in better equipment to rectify any faults or difficulties, even though this method is costly and finite. To achieve sustained improvement, homebrewers must adopt an analytical approach by gathering and analyzing data throughout the brewing process with a special focus on fermentation.

What Is Analytics?
What is analytics anyway? Before we jump into that, let’s identify a few things that analytics is NOT. Analytics is not intimidating, and it is not difficult. Anybody with an elementary understanding of mathematics can wield analytics as a tool in their brewing repertoire.
By definition, Analytics is “the patterns and other meaningful information gathered from the analysis of data.”1 Think of it like a method used by detectives – the data points are clues, the detective looks at all the clues and uses them to paint a picture, and then the detective looks at the whole picture to solve the mystery. Break it down into three simple steps:
- Gather Data (gravity, temperature, etc.)
- Transform Data (graphs and charts)
- Analyze (develop questions or answer them)
Most analytical projects begin with what’s called descriptive analysis, which recounts past events. But it’s not always about uncovering what happened, predictive analysis forecasts what is likely to happen in the future. A homebrewer might use descriptive analysis to figure out what happened with the last three batches of American Pale Ale and then use predictive analysis to predict what will happen with the fourth batch.

Analytics accommodates any kind of data, so don’t get wrapped up in the numbers. It’s just as easy (and more fun) to gather subjective data and analyze it in a similar fashion. Subjective data elements are things like taste, aroma, clarity, mouthfeel – anything you can gather with your senses. By collecting both objective and subjective data, you can compose a thorough foundation to analyze and improve your beer.
The difference lies in the graphics. Gathering data and compiling it into tables or spreadsheets yields tedious and unsatisfying returns. Although the answers are in the data, they are likely not immediately recognized. Transforming the raw data into a visual representation (i.e. – a graph or chart) changes your perspective and increases the rate at which you can process the data. According to an article by Thermopylae Sciences and Technology, “humans respond to and process visual data better than any other type of data… the human brain processes images 60,000 times faster than text, and 90 percent of information transmitted to the brain is visual.”2
Solve Problems
As a homebrewer, why should I care about analytics? It sounds like a lot of extra work and I’m not sure it’s worth my time, or even that I have the time – all legitimate concerns for the busy homebrewer. But you should care, because analytics can help homebrewers solve problems and identify new ones.

Consistency
Sustained consistency in brewing continues to be an ability that is nearly monopolized by professional breweries. For the homebrewer, recreating that perfect batch over and over again comes with great difficulty and maybe a little luck. Using analytics to track fermentation patterns will open your eyes to the world of inconsistencies that are likely hindering consistent results.
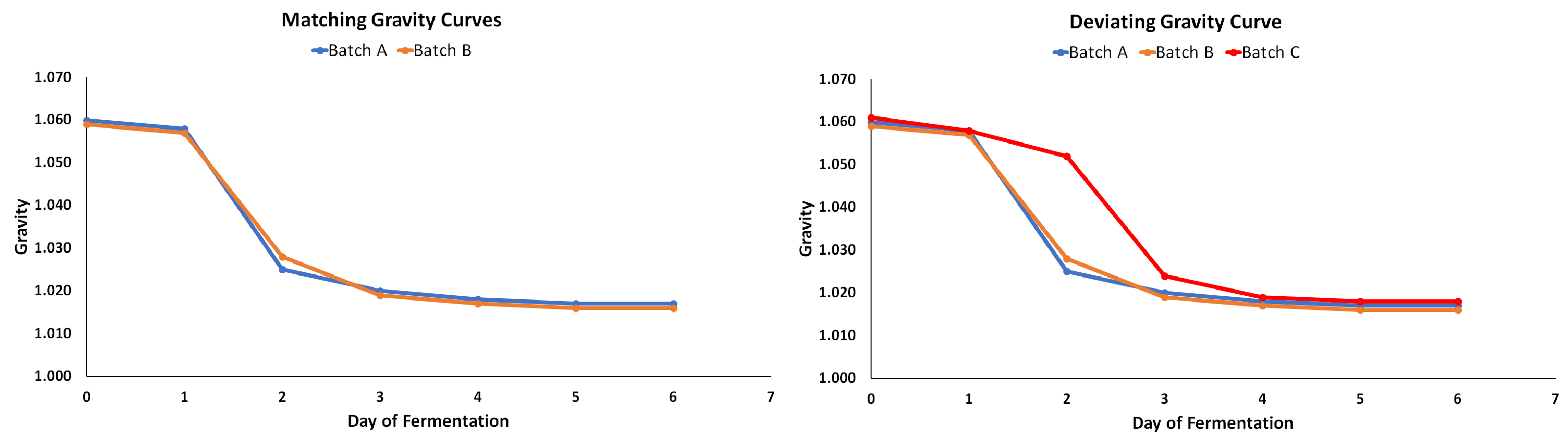
On brew day, you spend several hours creating wort – a liquid that yeast cells transform into beer. Given that you have consistent brew day habits, recreating that wort should come easy. It’s during the fermentation that minor inconsistencies blossom into major changes for your final product. Let’s say you brew Batch A and like the results, so you recreate it by brewing Batch B with the same recipe and methods. By gathering fermentation data (gravity and temperatures) throughout the process, you can create fermentation curves – a visual representation of changes in gravity over time – for each batch. After trying B, you find that the results are different than A. You know that the wort composition and characteristics matched for each batch and look to the fermentation pattern for any inconsistencies. Matching the shape of the fermentation curve from one batch to the next increases the likelihood of consistent results. When batches deviate from the “normal” curve for that particular recipe, you may begin to notice inconsistencies in the final product as a result of that deviation.
Predicting Final Gravity, Transfer Timing
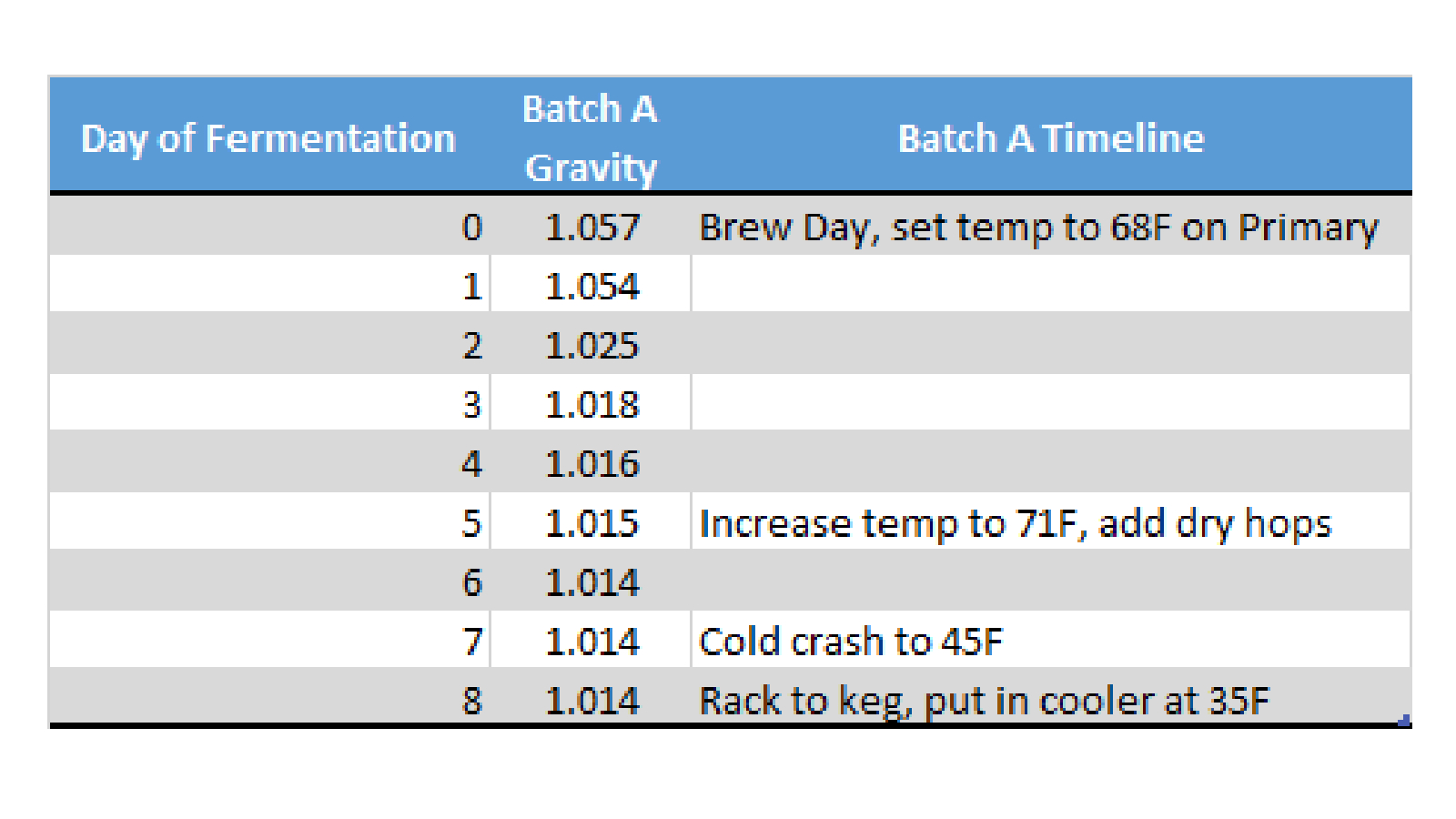
Rookie (and seasoned) brewers often struggle with determining when their beer is done fermenting. Has it reached final gravity? Can I transfer it to the secondary fermenter or keg it? Prematurely ending primary fermentation has many implications, mostly bad, that homebrewers often avoid by fermenting for a pre-determined amount of time, e.g., two weeks being a common timeframe. While this approach almost guarantees adequate attenuation, the beer likely sits on the yeast for longer than necessary, eating up time that could otherwise be occupied by a dedicated conditioning phase. Professional breweries, such as Deschutes, are using analytics to model their fermentation patterns to predict final gravity, making transfer timing and brewing schedules far more efficient. For the homebrewer with limited fermenter space, being able to ferment more batches in a shorter timeframe sounds ideal. The analytics of this plays out in a two-step process:
Step 1 – Compare past attenuation ranges of the yeast strain you are using
For strains that you have not brewed with before, look on the manufacturer’s website for the attenuation range, it will at least give you a place to start. For strains that you have brewed with before, compile a list of the attenuation values from any past batch that used the same yeast strain that you are using for your current batch.
Batches Using Strain X Attenuation Value
Batch C 80%
Batch D 75%
Batch E 70%
Batch F 73%
Using these attenuation values from past batches and the current batch’s original gravity (OG), calculate a list of final gravities (FG).
((OG – 1) x (1 – Atten.)) + 1 = FG
Convert the attenuation percentages to decimals (e.g. 80% -> 0.80)
Current Beer – Batch G
Original Gravity of G = 1.057
Atten. OG of Batch G FG
80% 1.057 1.011
75% 1.057 1.014
70% 1.057 1.017
73% 1.057 1.015
The highest and lowest final gravity values define the range the current beer should land in, giving you extreme upper and lower boundaries. Averaging all the final gravities suggests the most likely final gravity value for the current beer.
Upper FG Limit – 1.017
Lower FG Limit – 1.011
Average FG – 1.01425 –> round to 1.014
Put these values to work in a simple X-Y chart, graphing the upper, lower, and average values as horizontal lines.

And just like that, as early as brew day, you have a very clear and analytically sound prediction for this batch’s final gravity, and your chart is set up and ready to populate with fermentation data.
Step 2 – Confirm final gravity by analyzing the change in gravity on a fermentation curve
As your beer ferments and you add data, the fermentation curve begins to take shape, likely starting out with a gradual decline followed by a rapid drop during the yeast growth phase. As the yeast slow down and begin flocculating, the fermentation curve will begin to level out, with each day having a smaller change in gravity than the last. Visualizing the fermentation curve makes analyzing the change in gravity very easy. Simply put, when the gravity curve yields little to no change from one day to the next, primary fermentation is complete. The gravity curve should have leveled out within the final gravity range and should be close to the average final gravity value. If the gravity curve leveled out far beyond the final gravity range, then there may be an underlying issue. Given that the curve has leveled out at a reasonable value within the range, it’s safe to say that the beer is done fermenting and you are safe to take the next step in your process.

Gathering Data
You don’t need all the pieces of the puzzle to figure out what the picture is. But the more pieces that you fit together, the more detailed the image becomes. Brewing analytics works in a similar fashion – the more data a brewer gathers, the more insights they have into various aspects of the brewing process and its results.
Any homebrewer, veteran or rookie, knows all too well that this beloved pastime comes with an often lofty monetary demand. Equipment upgrades typically arise after an inner debate that inevitably starts with, “do I really need this?” and ends with “now I can’t pay my rent… but I think this will help.” The best part about getting started with data gathering? It’s free. Gathering a solid foundation of data requires very little, if any, extra equipment beyond what a novice brewer already has. The drawback comes with diligence on the part of the homebrewer to manually gather data throughout the fermentation and/or brewing process.
There are three fermentation metrics that yield the greatest analytical insights: Gravity, temperature, and timeline.
Gravity
Using a standard hydrometer, take a gravity reading once a day during fermentation. Homebrewers may be hesitant to do this daily, fearing oxidation and wasted beer. Oxidation, while possible (and likely negligible), is dependent on your set-up and handling practices. As for wasted beer – a standard graduated cylinder requires 150 mL of beer in order to take a gravity reading. Given a seven day primary fermentation and daily samples, that amounts to 2.2 pints, or 5.5% of a standard 5-gallon batch. Keep in mind that taking samples affords you the opportunity to also observe subjective aspects of your beer and assess for off flavors and aromas.

Temperature
The temperature of the beer in the fermenter strongly influences rate of fermentation and the resulting byproducts produced by the yeast. A word of caution – do not assume the temperature of the beer in the fermenter is equal to the temperature of a beer sample taken for a gravity. Ensure that you are tracking the fermenter beer temperature and not the sample temperature when you record your data. As you translate the data into a chart, be sure to define the upper and lower temperature limits of the yeast strain. Visualizing the temperature values provides a sense of how effectively you are maintaining consistent temperature and ensures that you are staying within the recommended temperature range for primary fermentation.

Timeline
Possibly the most unique metric, timeline data defines the relationship between results and events. Simply put, record what you did and when you did it. Timeline data becomes relevant when making correlations between your fermentation schedule and results.

Using the Numbers – Basic Analysis Methods
The data trio of gravity, temperature, and timeline affords homebrewers a solid foundation to work with. While entire volumes could be written on the subject of brewing data analysis, there are two methods worth mentioning. Both methods follow a simplistic approach to improving your beer through analytics and can yield results early on.
Batch Comparison
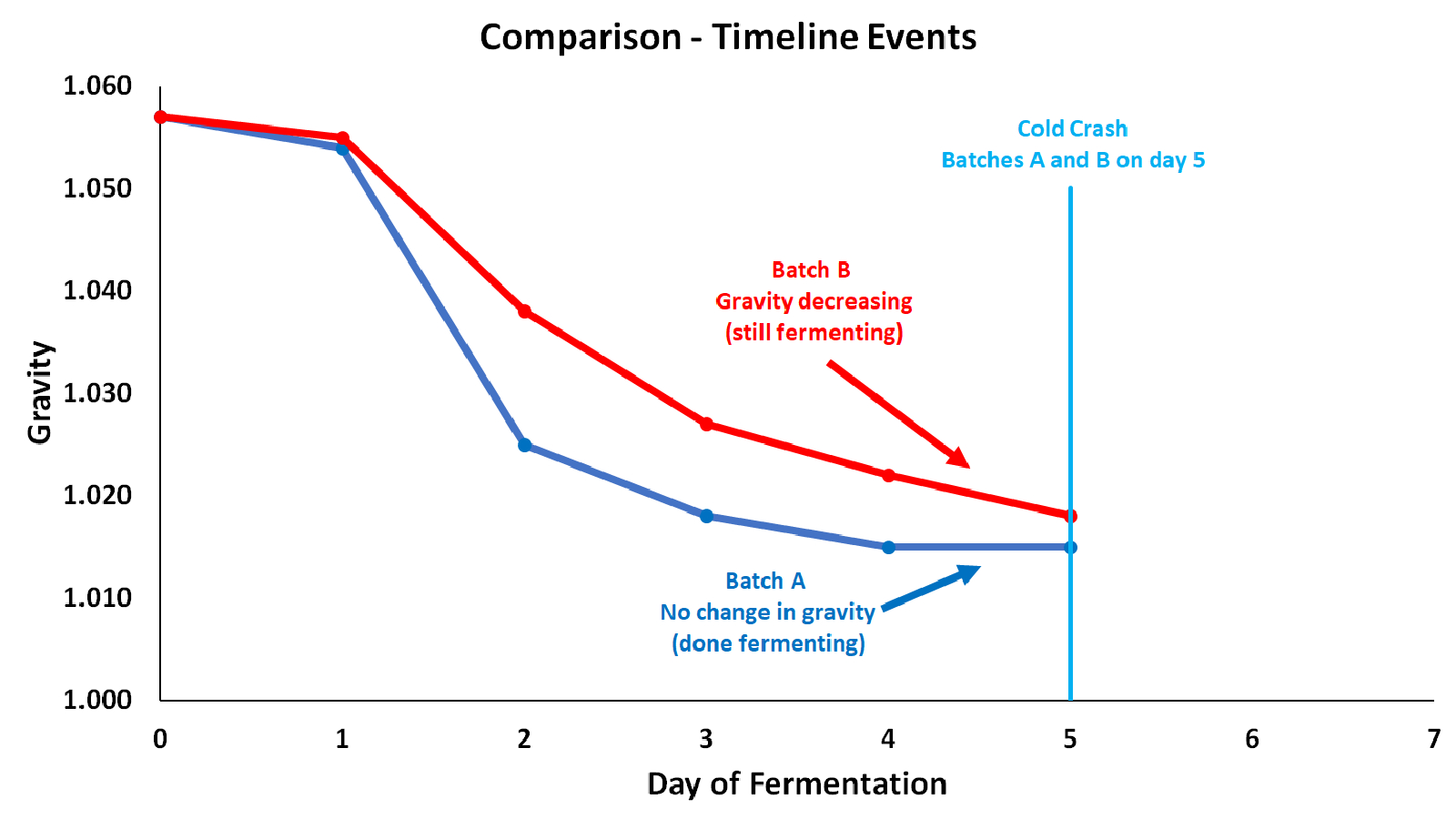
Brewers compare beer all the time, regularly carrying out side-by-side taste tests and blind taste tests – looking, tasting, and assessing one final product against another. The end goal, especially when comparing batches of the same recipe, usually revolves around defining improvement. Is Batch B better than Batch A? While this conclusion comes easily, the follow-up question every brewer should ask is, “Why is Batch B better/worse than Batch A?” As a brewer, your analytical endgame is to achieve sustained improvement, and you can do this by comparing batch data. Start by creating overlapping fermentation curves, as this provides a visual representation of any inconsistencies among batches. While the shape of the curve is important and easy to contrast against others, pay special attention to your timeline data. Make correlations between when you did something and what happened – for example, say you cold crashed both Batch A and Batch B after 5 days in primary. What was the gravity of each when you crashed? Could this have affected the final results?
Trend Recognition
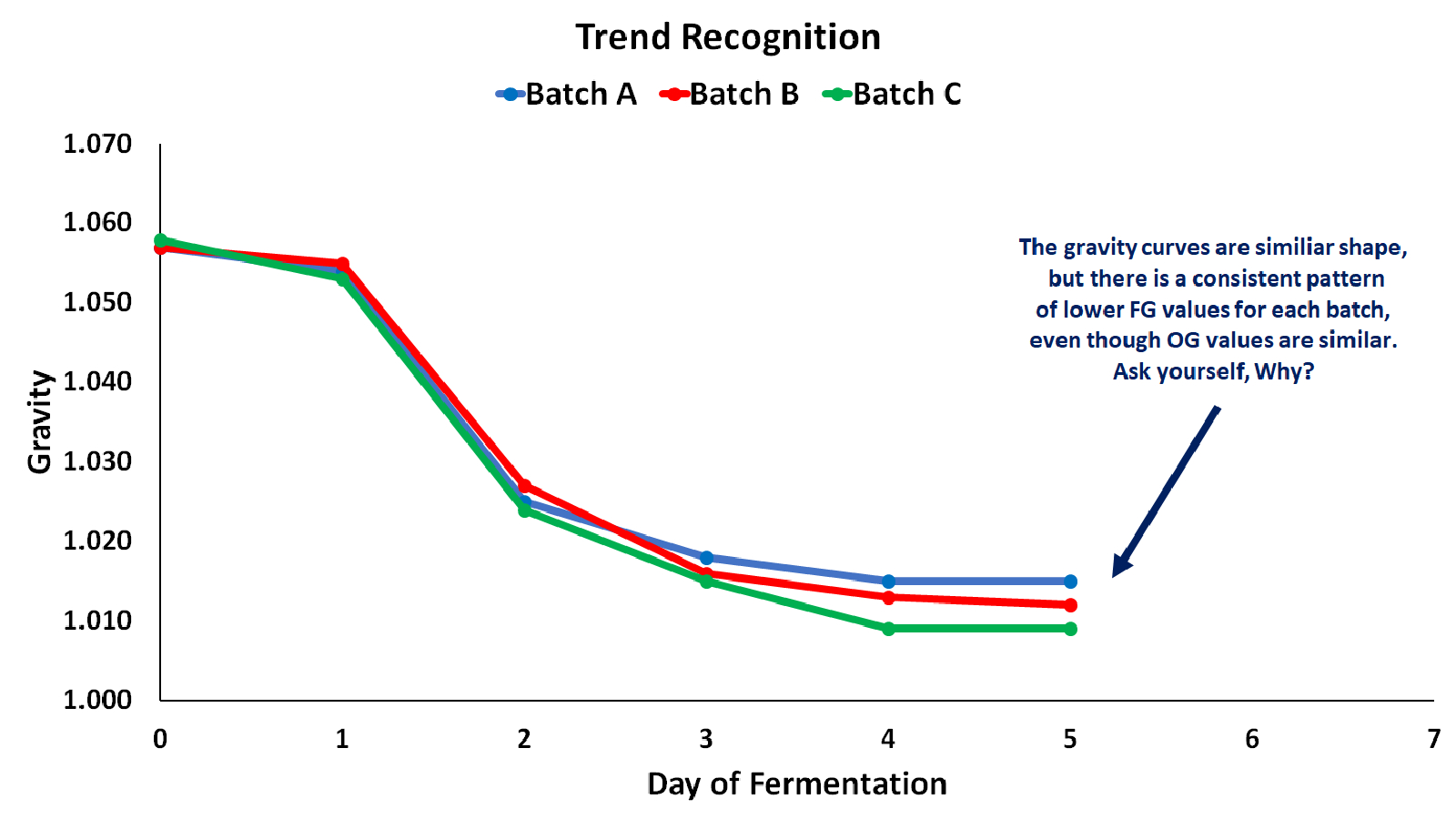
Remember, analytics is all about finding patterns and assigning meaning to them. Trend recognition is simply finding commonalities between results – this is particularly applicable to yeast performance. By comparing fermentation curves, brewers have the opportunity to identify patterns with a given yeast strain and how it reacts to various actions that you take throughout fermentation. For example, Batches A, B, and C were brewed with the same recipe and yeast strain. After analyzing the fermentation curves, you notice that all three batches had similar fermentation patterns, but each batch had a slightly lower final gravity than the previous one. While you might not immediately have an answer as to why this pattern occurs, you have identified a pattern nonetheless, and you can either take corrective actions on future batches to remedy negative outcomes or continue actions that tend towards positive outcomes.
Conclusion
When applied to homebrewing, analytics allows boundless opportunities for improvement by using data to uncover hidden patterns. Transforming fermentation data into graphics greatly enhances our ability to extrapolate meaning from data and gives the brewer an analytically sound foundation from which to make adjustments. Insights gained through analysis may not always manifest in the form of answers, but rather questions, that help to steer you in the right direction. Homebrewers of any level should embrace analytics as an affordable and credible way of achieving sustained improvement in brewing.
| About The Author |
 Patrick Murphy is a homebrewer and founder of Arithmech Analytics, a software company dedicated to helping brewers of any level improve their beer through analytics. When he’s not developing software or writing about the brewing community, you can find him blasting punk rock and brewing beer. Patrick lives with his wife and two dogs in New Orleans and has been homebrewing since 2013.
Patrick Murphy is a homebrewer and founder of Arithmech Analytics, a software company dedicated to helping brewers of any level improve their beer through analytics. When he’s not developing software or writing about the brewing community, you can find him blasting punk rock and brewing beer. Patrick lives with his wife and two dogs in New Orleans and has been homebrewing since 2013.
Sources
1 – https://www.dictionary.com/browse/analytics?s=t
2 – http://www.t-sciences.com/news/humans-process-visual-data-better
If you have any thoughts related to this article, please do not hesitate to share them in the comments section below!
Support Brülosophy In Style!

All designs are available in various colors and sizes on Amazon!
Follow Brülosophy on:
FACEBOOK | TWITTER | INSTAGRAM

If you enjoy this stuff and feel compelled to support Brulosophy.com, please check out the Support page for details on how you can very easily do so. Thanks!





17 thoughts on “Better Beer Through Brewing Analytics”
Interesting article, Patrick. I think this wave of thinking about homebrewing and Numbers makes for one obvious conclusion; Marshall should start developing that relationship with the folks over at https://tilthydrometer.com/.
I also wonder how the world of analytics would lend itself to Shellhammer’s work on hops and the saturation point of dry hopping.
I have used the Tilt for over 2 years now on many batches. I love the data it provides but it does have it’s flaws. One major complaint I have is krausen often attaches to the tilt hydrometer and scews the gravity reading for the remainder of fermentation, rendering the tool useless.
Wow, I need that hydrometer now. Automation!
I think it would have been a better article if you had replaced ‘must’ with ‘can’.
I tend to be of the Charlie Papazian school of homebrew: relax, don’t worry, have a homebrew. And from my job as automation engineer, keep it stupid simple.
Also, do not assume about the amounts that homebrewers brew, I have already seen a lot of people on different forums (UK, AUS, NL, B, DE) who brew between 5 and 10 litre, myself included.
I would also hypothesize that if a homebrewer wants this level of detail, he will already have bought tools like Plaato for gravity, and sensors and applications for registering temperature.
The rest will probably be content if they have a proper way of storing their recipe so that they can duplicate it in volume, ingredients and yeast, mash steps and hopping rates.
I think this article is more like part of a master class, but I find it contrasting with the spirit of Brülosophy which seems to me really about “why would we care about that? Let us perform an experiment to see if it really matters!”.
I understand what you’re saying, but I think there is a bigger goal here.
Much like the UK food initiative, eat 5 pieces of fruit & veg a day, getting hung up on the numbers, grams, litres and other details of this article is only going to be of limited benefit, rather, getting the brewer to think about what they’re doing and take control of their own process (in their own way with their own numbers) is what will count. Its more about mindset.
For example: I was employed as a postdoc research assistant in a lab for some years and one day (very early on In my career I must add!) I approached my lab head with a promising result. I was pleased. When my supervisor questioned me about the specifics of what I had done in this particular experiment I was a bit vague as I wasn’t sure. An experiment that shows no difference but where you know what you did is infinitely more useful than a interesting result that you don’t know how you got there. I got told off, rightly.
The point is, whether you have made a bad or good beer and you know what you did, then you can improve. If you’ve made a great beer, but didn’t take the time and effort to understand how you made that beer (and the variables that made it good) then you are no better a brewer than you were before, you’ve not progressed, because there is little assurance that you re-create it.
I may be in a minority here, but I don’t brew beer primarily so I can drink beer. I brew beer because i want to create something. For me it’s the pursuit. It’s just a bonus I do like beer.
This article isn’t exhaustive (how could it be?), but if it motivates a home brewer to examine their practice, even if it requires looking elsewhere, then that is a success
The article is not wrong, but scientists have collected/ analyzed data for ages. The only thing new here is the buzzword.
Also…
Not many homebrewers brew the same beer over and over. Those who do, already collect and analyze data looking for patterns, so again, nothing new.
True, but you don’t have to brew the exact same beer to make use of similar trends. There are more similarities in grists than differences for most brews. Commercial breweries focus on making the exact same beer, but for the homebrewer who is essentially continually developing recipes, knowing how your yeast behaves with a similar malt bill allows you to take out some of the guess work and know within reason how to balance your beer with regards bitterness, residual sugars and mineral content. You need to have a few data points to know the bounds of what you’re working with, so that’s where some analytics come in.
I agree with you about people being already decided. I think that there are three types of homebrewer. One that measures as much as they can and re-evaluates, the other is the “throw it and see what happens” and the third takes some precautions but will religiously make a beer like they always have and never change their process regardless of whether the last beer was worse or better than the first. If you are happy then that’s all that matters. I personally know one of each.
Maybe this article will appeal to the outliers?
You bring up an excellent point when you said it’s not necessary to brew the same beer to make use of similar trends. I struggled with this concept when writing the article, simply because there are SO MANY ways that you can approach analyzing beer. Do I compare batches with similar recipes? Do I take it from the yeasts’ perspective and follow trends in performance or outcome? As you mentioned, homebrewers are constantly changing and developing recipes. This makes it difficult to compare one batch to another if the recipes and/or methods vary. From an analytical standpoint, there is almost always overlapping aspects, such as common yeast strain, grist makeup, etc. Looking for commonalities such as these still allows you the opportunity to uncover trends in your brewing and compare batch to batch even if they’re from different recipes. Thanks for the comment!
As a homebrewer, I already obsess over way too many details. I think most homebrewers tend to overthink our hobby, it’s what we enjoy so it’s a natural to spend a lot of time pondering the topic. This takes the brewing obsession to the Nth degree. I’m glad you find joy in analytics, but it’s not for me.
I enjoyed this posting as it has given me a different way to look at my hobby. For the most part, I rarely brew the same recipe twice. Heck, with all the varieties of yeast, malts and hops, I just can’t wait to try something new. With that said, I recently brewed a Rye Pale Ale that was well received (ok, my small group of friends raved about it). Now, I’m planning to brew it again, which in the grand scheme of things could be boring. I keep reasonable records. I keep them primarily to see where I might have gone wrong if someone is critical of my brew. (rarely are my friends and relatives so helpful)
This posting gives me a new perspective. A way to compare each new brew against expectations, and against prior brews of the same recipe.
Thanks!
Hi Chal! Although I only touched on it briefly, doing “subjective analysis” is a great alternative to “numbers analysis” for the brewer who rarely repeats the same recipe. Since most of your batches are unrelated it may be difficult to compare numbers. I’d encourage you to gather other types of data to help you visualize any trends in your overall brewing. For example, I give each of my beers an overall score. This is unrelated to the type of beer it is, and simply stands as a guideline for how satisfied I was with the beer. Keep it simple, rate your beers on an A through F scale, give it to friends and family to do the same, and then keep track of your scores. Over time, you can see general trends in your brewing. Thanks for the comment and I hope that second batch of Rye Pale Ale turns out great!
As a guy who makes a living in Process Improvement and Automation, I love this concept and am doing much of it myself. The “automation” side here, as you note, costs money, but it does seem the data can be gathered manually. A couple simple questions from my side…
1) Regarding hydrometer readings and wasted beer. I have never even considered tossing out the beer from the graduated cylinder…90% of it goes back into the carboy, and maybe I take a swig of what’s left. Is this practice completely frowned upon due to oxidation concerns? I guess I’ve just always been doing this for fear of wasting precious beer.
2) Regarding temperature readings. What are the thoughts on accuracy of a temp controller probe attached to the side of a plastic carboy inside the fermentation chamber? I’ve always felt it is close enough to measuring liquid rather than ambient temp, but wondering if that’s another easy area for improvement with something like a thermowell.
I do think one challenge here, as noted by other commenters, could be insufficient volume of data. While we all may have a couple go-to recipes, it is just going to take time and diligence to get meaningful data out of maybe a couple iterations of the same beer in a year. Obviously nothing like commercial scale and frequency. But still, if we stretch the concept a bit and group very similar beers (same yeast, style, maybe slightly different grain bill) I think we can come up with enough meaningful information to get some trending data, and then use that for process improvement within our brewhouses.
Cheers!
I think adding your sample beer back into the fermenter is totally fine, given that you have a clean hydrometer and graduated cylinder. I suppose that’s why I’ve never added my sample beer back in, just paranoia about infection. As for oxidation, I imagine it’s negligible. Although smaller batches may be more susceptible to it. If anyone has a more scientific answer for the oxidation possibilities, please weigh in.
The last section on your original comment is fantastic. This is exactly the kind of mindset that homebrewers need to make analytics work for them. Professional brewers have the luxury of technology, funds, time,…, whereas a homebrewer may only have a few data points about a few batches scribbled on a piece of paper. You nailed it – start making what you have work for you. It doesn’t have to be complex, keep it simple and work up from there.
Out of curiosity, what data do you gather and how do you use it?
I’m basically logging entries using an online tool (Brewers Friend) against my recipes, but not using it to the full capacity. This post inspired me to take this off the backburner so now I’ve also got a google sheet up and running…only took about 30 min to get this year’s brews logged.
Brew Log raw data:
Brew Date – % Base malt – % Dark – % Flaked – % Other – Yeast – OG
Then, I’ll track up to 5 gravity readings with 3 columns each: elapsed days, gravity, and Y/N if I added any ingredients to the fermenter (who knows?) like dry hops, fruit, etc.
Now I can run all of the analytics I want off a centralized sheet with pretty low effort. It will be very useful for general categories I use most, like IPA fermented with US-05. For instance, my average attenuation is at 75% so perhaps I am under-pitching or not being careful enough with temp control.
Down the data rabbit hole I go!
Also, of course the concern was infection…not sure how I didn’t think of that. I guess I just assumed a sanitized cylinder + some alcohol content in the beer means no worries 🙂
I personally have adjusted my recent brews (NEIPAs) based on metrics I gathered from previous similar brews. I operate a BrewPi and using the delta between the beer and incubator temperature I could calculate the thermal activity of the beer and graph this as a guide to measure how far along the beer was (supplemented with gravity readings).
I found that the yeast strain I have been harvesting (WLP4000) was taking longer to ferment and slightly lower attenuation on successive generations despite growing up yeast on a spin plate the same before every brew. My grists were slightly different, but seeing the graph showed me it was the yeast behaving different rather than anything else. Primary fermentation was increasing from 8 days to 12 days for *complete* fermentation (the last few points trickled along). My previous brews using S05 dry yeast (fresh pack in yeast stir plate starter) showed whatever my high gravity grist, beers peaked 24-48 hours in and were complete by the 7th day. Graph plots looked pretty much the same each time.
The upshot is, knowing this, how the two yeasts attenuated under different conditions I blended the two yeasts. My last beer fermented in the same time frame as S05 in a very predictable manner but with the ester production of WLP4000. I used previous beers to adjust my grist/dextrose to achieve the same attenuation as WLP4000 alone.
I feel this approach is more appropriate for a brewer that likes to perfect something that is objectively good to start, which takes commitment to put the creative side on hold.
I do this quite often with my core recipes. For example, I have 8 iterations of a recipe for an American Pale Ale that made it to the final round of NHC. Upon the first batch, I recognized it was a damn good beer, so how can I make it better? After noting all the pros to the beer, I looked for the cons and made incremental tweaks to my recipe/temps/pitch rates with each consecutive iteration, taking detailed notes on anything I could readily measure. Sure, there were a few steps backward, but I have data to show the direct, probable cause.
The analytical approach really only makes sense if you have precise control of a lot of the variables, i.e temp control, mash ph, healthy yeast etc. If your mash ph changes with every batch, you’ll have a different beer every time. Also, if you’re making hoppy beer, the hops in that little one ounce bag could be completely different year to year. Pro brewers have much more control of this by having relationships with the hop farms.
With all that said, applying data to visual chart might make it even easier for me to spot trends that match tasting notes. It’s definitely a great idea!